Ignite UI for Angular 19.2 is here and it introduces a major update to SSR (Server Side Rendering) and SSG (Prerendering), plus a brand-new component – Angular Tile Manager. Read more about these enhancements.
The App Builder Blog

Because of security concerns and code visibility, major corporations work with paid open-source software. Free open-source platforms, on the other hand, are the go-to choice for individual devs or small companies and startups with limited budgets.
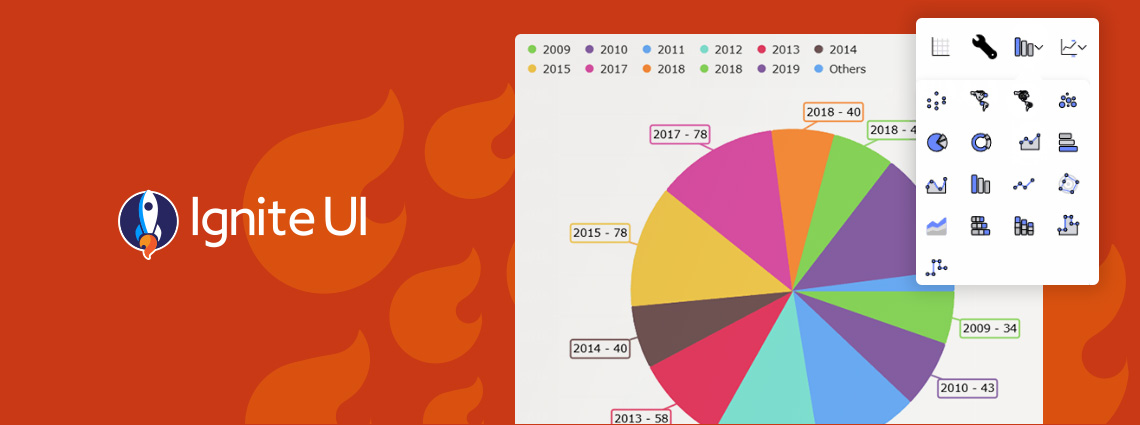
We are extremely excited to introduce a brand-new charting functionality – Dashboard Tile. Learn how to use this charting feature to build interactive Dashboards with almost no hand-coding at all.
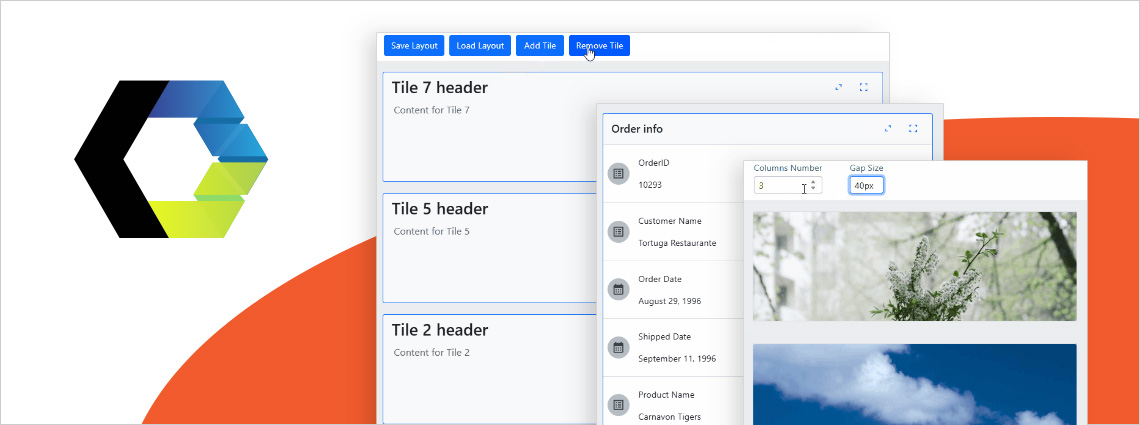
Ensuring ultimate app development flexibility and agility with the components you use is key. That's why we've added a new component to the Ignite UI for Web Components toolbox - Tile Manager. Check out its properties and see how to use it.

Ignite UI for Angular 19.1 comes with powerful new capabilities, including Query Builder and Carousel component. Learn more in this release blog post.
With the year coming to a close, we are reflecting on all the milestones and updates we've made. Here is Ignite UI 2024 in review. Read more in this blog post.
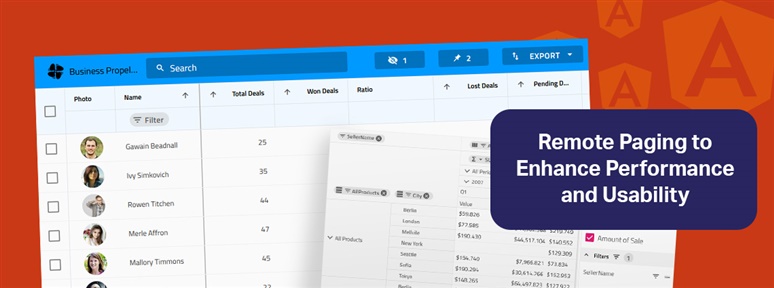
See how to extend your Web API to support remote paging capabilities and how to integrate backend services in Angular Grid with Ignite UI for Angular.

Do you know how to handle internationalization and localization (l10n) in Angular Data Grids? Read this post to find code snippets, explanations, and more.

Ignite UI for Angular enables you to build data-heavy UIs with grids, charts, and more. But what are the other reasons that make it stand out? Learn more.
It’s release time and this time around Infragistics Ultimate 24.1 brings a host of new and much-anticipated features! See what’s new in our blog.